In Part 6 of this series, I showed how to create a very basic COM-based input format provider for Log Parser. I wrote that blog post as a follow-up to an earlier blog post where I had written a more complex COM-based input format provider for Log Parser that worked with FTP RSCA events. My original blog post had resulted in several requests for me to write some easier examples about how to get started writing COM-based input format providers for Log Parser, and those appeals led me to write my last blog post:
Advanced Log Parser Part 6 - Creating a Simple Custom Input Format Plug-In
The example in that blog post simply returns static data, which was the easiest example that I could demonstrate.
For this follow-up blog post, I will illustrate how to create a simple COM-based input format plug-in for Log Parser that you can use as a generic provider for consuming data in text-based log files. Please bear in mind that this is just an example to help developers get started writing their own COM-based input format providers; you might be able to accomplish some of what I will demonstrate in this blog post by using the built-in Log Parser functionality. That being said, this still seems like the best example to help developers get started because consuming data in text-based log files was the most-often-requested example that I received.
In Review: Creating COM-based plug-ins for Log Parser
In my earlier blog posts, I mentioned that a COM plug-in has to support several public methods. You can look at those blog posts when you get the chance, but it is a worthwhile endeavor for me to copy the following information from those blog posts since it is essential to understanding how the code sample in this blog post is supposed to work.
| Method Name | Description |
| OpenInput |
Opens your data source and sets up any initial environment settings. |
| GetFieldCount |
Returns the number of fields that your plug-in will provide. |
| GetFieldName |
Returns the name of a specified field. |
| GetFieldType |
Returns the datatype of a specified field. |
| GetValue |
Returns the value of a specified field. |
| ReadRecord |
Reads the next record from your data source. |
| CloseInput |
Closes your data source and cleans up any environment settings. |
Once you have created and registered a COM-based input format plug-in, you call it from Log Parser by using something like the following syntax:
logparser.exe "SELECT * FROM FOO" -i:COM -iProgID:BAR
In the preceding example, FOO is a data source that makes sense to your plug-in, and BAR is the COM class name for your plug-in.
Creating a Generic COM plug-in for Log Parser
As I have done in my previous two blog posts about creating COM-based input format plug-ins, I'm going to demonstrate how to create a COM component by using a scriptlet since no compilation is required. This generic plug-in will parse any text-based log files where records are delimited by CRLF sequences and fields/columns are delimited by a separator that is defined as a constant in the code sample.
To create the sample COM plug-in, copy the following code into a text file, and save that file as "Generic.LogParser.Scriptlet.sct" to your computer. (Note: The *.SCT file extension tells Windows that this is a scriptlet file.)
<SCRIPTLET>
<registration
Description="Simple Log Parser Scriptlet"
Progid="Generic.LogParser.Scriptlet"
Classid="{4e616d65-6f6e-6d65-6973-526f62657274}"
Version="1.00"
Remotable="False" />
<comment>
EXAMPLE: logparser "SELECT * FROM 'C:\foo\bar.log'" -i:COM -iProgID:Generic.LogParser.Scriptlet
</comment>
<implements id="Automation" type="Automation">
<method name="OpenInput">
<parameter name="strFileName"/>
</method>
<method name="GetFieldCount" />
<method name="GetFieldName">
<parameter name="intFieldIndex"/>
</method>
<method name="GetFieldType">
<parameter name="intFieldIndex"/>
</method>
<method name="ReadRecord" />
<method name="GetValue">
<parameter name="intFieldIndex"/>
</method>
<method name="CloseInput">
<parameter name="blnAbort"/>
</method>
</implements>
<SCRIPT LANGUAGE="VBScript">
Option Explicit
' Define the column separator in the log file.
Const strSeparator = "|"
' Define whether the first row contains column names.
Const blnHeaderRow = True
' Define the field type constants.
Const TYPE_INTEGER = 1
Const TYPE_REAL = 2
Const TYPE_STRING = 3
Const TYPE_TIMESTAMP = 4
Const TYPE_NULL = 5
' Declare variables.
Dim objFSO, objFile, blnFileOpen
Dim arrFieldNames, arrFieldTypes
Dim arrCurrentRecord
' Indicate that no file has been opened.
blnFileOpen = False
' --------------------------------------------------------------------------------
' Open the input session.
' --------------------------------------------------------------------------------
Public Function OpenInput(strFileName)
Dim tmpCount
' Test for a file name.
If Len(strFileName)=0 Then
' Return a status that the parameter is incorrect.
OpenInput = 87
blnFileOpen = False
Else
' Test for single-quotes.
If Left(strFileName,1)="'" And Right(strFileName,1)="'" Then
' Strip the single-quotes from the file name.
strFileName = Mid(strFileName,2,Len(strFileName)-2)
End If
' Open the file system object.
Set objFSO = CreateObject("Scripting.Filesystemobject")
' Verify that the specified file exists.
If objFSO.FileExists(strFileName) Then
' Open the specified file.
Set objFile = objFSO.OpenTextFile(strFileName,1,False)
' Set a flag to indicate that the specified file is open.
blnFileOpen = true
' Retrieve an initial record.
Call ReadRecord()
' Redimension the array of field names.
ReDim arrFieldNames(UBound(arrCurrentRecord))
' Loop through the record fields.
For tmpCount = 0 To (UBound(arrFieldNames))
' Test for a header row.
If blnHeaderRow = True Then
arrFieldNames(tmpCount) = arrCurrentRecord(tmpCount)
Else
arrFieldNames(tmpCount) = "Field" & (tmpCount+1)
End If
Next
' Test for a header row.
If blnHeaderRow = True Then
' Retrieve a second record.
Call ReadRecord()
End If
' Redimension the array of field types.
ReDim arrFieldTypes(UBound(arrCurrentRecord))
' Loop through the record fields.
For tmpCount = 0 To (UBound(arrFieldTypes))
' Test if the current field contains a date.
If IsDate(arrCurrentRecord(tmpCount)) Then
' Specify the field type as a timestamp.
arrFieldTypes(tmpCount) = TYPE_TIMESTAMP
' Test if the current field contains a number.
ElseIf IsNumeric(arrCurrentRecord(tmpCount)) Then
' Test if the current field contains a decimal.
If InStr(arrCurrentRecord(tmpCount),".") Then
' Specify the field type as a real number.
arrFieldTypes(tmpCount) = TYPE_REAL
Else
' Specify the field type as an integer.
arrFieldTypes(tmpCount) = TYPE_INTEGER
End If
' Test if the current field is null.
ElseIf IsNull(arrCurrentRecord(tmpCount)) Then
' Specify the field type as NULL.
arrFieldTypes(tmpCount) = TYPE_NULL
' Test if the current field is empty.
ElseIf IsEmpty(arrCurrentRecord(tmpCount)) Then
' Specify the field type as NULL.
arrFieldTypes(tmpCount) = TYPE_NULL
' Otherwise, assume it's a string.
Else
' Specify the field type as a string.
arrFieldTypes(tmpCount) = TYPE_STRING
End If
Next
' Temporarily close the log file.
objFile.Close
' Re-open the specified file.
Set objFile = objFSO.OpenTextFile(strFileName,1,False)
' Test for a header row.
If blnHeaderRow = True Then
' Skip the first row.
objFile.SkipLine
End If
' Return success status.
OpenInput = 0
Else
' Return a file not found status.
OpenInput = 2
End If
End If
End Function
' --------------------------------------------------------------------------------
' Close the input session.
' --------------------------------------------------------------------------------
Public Function CloseInput(blnAbort)
' Free the objects.
Set objFile = Nothing
Set objFSO = Nothing
' Set a flag to indicate that the specified file is closed.
blnFileOpen = False
End Function
' --------------------------------------------------------------------------------
' Return the count of fields.
' --------------------------------------------------------------------------------
Public Function GetFieldCount()
' Specify the default value.
GetFieldCount = 0
' Test if a file is open.
If (blnFileOpen = True) Then
' Test for the number of field names.
If UBound(arrFieldNames) > 0 Then
' Return the count of fields.
GetFieldCount = UBound(arrFieldNames) + 1
End If
End If
End Function
' --------------------------------------------------------------------------------
' Return the specified field's name.
' --------------------------------------------------------------------------------
Public Function GetFieldName(intFieldIndex)
' Specify the default value.
GetFieldName = Null
' Test if a file is open.
If (blnFileOpen = True) Then
' Test if the index is valid.
If intFieldIndex<=UBound(arrFieldNames) Then
' Return the specified field name.
GetFieldName = arrFieldNames(intFieldIndex)
End If
End If
End Function
' --------------------------------------------------------------------------------
' Return the specified field's type.
' --------------------------------------------------------------------------------
Public Function GetFieldType(intFieldIndex)
' Specify the default value.
GetFieldType = Null
' Test if a file is open.
If (blnFileOpen = True) Then
' Test if the index is valid.
If intFieldIndex<=UBound(arrFieldTypes) Then
' Return the specified field type.
GetFieldType = arrFieldTypes(intFieldIndex)
End If
End If
End Function
' --------------------------------------------------------------------------------
' Return the specified field's value.
' --------------------------------------------------------------------------------
Public Function GetValue(intFieldIndex)
' Specify the default value.
GetValue = Null
' Test if a file is open.
If (blnFileOpen = True) Then
' Test if the index is valid.
If intFieldIndex<=UBound(arrCurrentRecord) Then
' Return the specified field value based on the field type.
Select Case arrFieldTypes(intFieldIndex)
Case TYPE_INTEGER:
GetValue = CInt(arrCurrentRecord(intFieldIndex))
Case TYPE_REAL:
GetValue = CDbl(arrCurrentRecord(intFieldIndex))
Case TYPE_STRING:
GetValue = CStr(arrCurrentRecord(intFieldIndex))
Case TYPE_TIMESTAMP:
GetValue = CDate(arrCurrentRecord(intFieldIndex))
Case Else
GetValue = Null
End Select
End If
End If
End Function
' --------------------------------------------------------------------------------
' Read the next record, and return true or false if there is more data.
' --------------------------------------------------------------------------------
Public Function ReadRecord()
' Specify the default value.
ReadRecord = False
' Test if a file is open.
If (blnFileOpen = True) Then
' Test if there is more data.
If objFile.AtEndOfStream Then
' Flag the log file as having no more data.
ReadRecord = False
Else
' Read the current record.
arrCurrentRecord = Split(objFile.ReadLine,strSeparator)
' Flag the log file as having more data to process.
ReadRecord = True
End If
End If
End Function
</SCRIPT>
</SCRIPTLET>
After you have saved the scriptlet code to your computer, you register it by using the following syntax:
regsvr32 Generic.LogParser.Scriptlet.sct
At the very minimum, you can now use the COM plug-in with Log Parser by using syntax like the following:
logparser "SELECT * FROM 'C:\Foo\Bar.log'" -i:COM -iProgID:Generic.LogParser.Scriptlet
Next, let's analyze what this sample does.
Examining the Generic Scriptlet in Detail
Here are the different parts of the scriptlet and what they do:
- The <registration> section of the scriptlet sets up the COM registration information; you'll notice the COM component class name and GUID, as well as version information and a general description. (Note that you should generate your own GUID for each scriptlet that you create.)
- The <implements> section declares the public methods that the COM plug-in has to support.
- The <script>section contains the actual implementation:
- The first part of the script section declares the global variables that will be used:
- The strSeparator constant defines the delimiter that is used to separate the data between fields/columns in a text-based log file.
- The blnHeaderRow constant defines whether the first row in a text-based log file contains the names of the fields/columns:
- If set to True, the plug-in will use the data in the first line of the log file to name the fields/columns.
- If set to False, the plug-in will define generic field/column names like "Field1", "Field2", etc.
- The second part of the script contains the required methods:
- The OpenInput() method performs several tasks:
- Locates and opens the log file that you specify in your SQL statement, or returns an error if the log file cannot be found.
- Determines the number, names, and data types of fields/columns in the log file.
- The CloseInput() method cleans up the session by closing the log file and destroying objects.
- The GetFieldCount() method returns the number of fields/columns in the log file.
- The GetFieldName() method returns the name of a field/column in the log file.
- The GetFieldType() method returns the data type of a field/column in the log file. As a reminder, Log Parser supports the following five data types for COM plug-ins: TYPE_INTEGER, TYPE_REAL, TYPE_STRING, TYPE_TIMESTAMP, and TYPE_NULL.
- The GetValue() method returns the data value of a field/column in the log file.
- The ReadRecord() method moves to the next line in the log file. This method returns True if there is additional data to read, or False when the end of data is reached.
Next, let's look at how to use the sample.
Using the Generic Scriptlet with Log Parser
As a sample log file for this blog, I'm going to use the data in the Sample XML File (books.xml) from MSDN. By running a quick Log Parser query that I will show later, I was able to export data from the XML file into text file named "books.log" that represents an example of a simple log file format that I have had to work with in the past:
id|publish_date|author|title|price
bk101|2000-10-01|Gambardella, Matthew|XML Developer's Guide|44.950000
bk102|2000-12-16|Ralls, Kim|Midnight Rain|5.950000
bk103|2000-11-17|Corets, Eva|Maeve Ascendant|5.950000
bk104|2001-03-10|Corets, Eva|Oberon's Legacy|5.950000
bk105|2001-09-10|Corets, Eva|The Sundered Grail|5.950000
bk106|2000-09-02|Randall, Cynthia|Lover Birds|4.950000
bk107|2000-11-02|Thurman, Paula|Splish Splash|4.950000
bk108|2000-12-06|Knorr, Stefan|Creepy Crawlies|4.950000
bk109|2000-11-02|Kress, Peter|Paradox Lost|6.950000
bk110|2000-12-09|O'Brien, Tim|Microsoft .NET: The Programming Bible|36.950000
bk111|2000-12-01|O'Brien, Tim|MSXML3: A Comprehensive Guide|36.950000
bk112|2001-04-16|Galos, Mike|Visual Studio 7: A Comprehensive Guide|49.950000
In this example, the data is pretty easy to understand - the first row contains the list of field/column names, and the fields/columns are separated by the pipe ("|") character throughout the log file. That being said, you could easily change my sample code to use a different delimiter that your custom log files use.
With that in mind, let's look at some Log Parser examples.
Example #1: Retrieving Data from a Custom Log
The first thing that you should try is to simply retrieve data from your custom plug-in, and the following query should serve as an example:
logparser "SELECT * FROM 'C:\sample\books.log'" -i:COM -iProgID:Generic.LogParser.Scriptlet
The above query will return results like the following:
| id | publish_date | author | title | price |
| ----- | ------------------ | -------------------- | ------------------------------------- | --------- |
| bk101 |
10/1/2000 0:00:00 |
Gambardella, Matthew |
XML Developer's Guide |
44.950000 |
| bk102 |
12/16/2000 0:00:00 |
Ralls, Kim |
Midnight Rain |
5.950000 |
| bk103 |
11/17/2000 0:00:00 |
Corets, Eva |
Maeve Ascendant |
5.950000 |
| bk104 |
3/10/2001 0:00:00 |
Corets, Eva |
Oberon's Legacy |
5.950000 |
| bk105 |
9/10/2001 0:00:00 |
Corets, Eva |
The Sundered Grail |
5.950000 |
| bk106 |
9/2/2000 0:00:00 |
Randall, Cynthia |
Lover Birds |
4.950000 |
| bk107 |
11/2/2000 0:00:00 |
Thurman, Paula |
Splish Splash |
4.950000 |
| bk108 |
12/6/2000 0:00:00 |
Knorr, Stefan |
Creepy Crawlies |
4.950000 |
| bk109 |
11/2/2000 0:00:00 |
Kress, Peter |
Paradox Lost |
6.950000 |
| bk110 |
12/9/2000 0:00:00 |
O'Brien, Tim |
Microsoft .NET: The Programming Bible |
36.950000 |
| bk111 |
12/1/2000 0:00:00 |
O'Brien, Tim |
MSXML3: A Comprehensive Guide |
36.950000 |
| bk112 |
4/16/2001 0:00:00 |
Galos, Mike |
Visual Studio 7: A Comprehensive Guide |
49.950000 |
| |
|
|
|
|
| Statistics: |
|
| ----------- |
|
| Elements processed: |
12 |
| Elements output: |
12 |
| Execution time: |
0.16 seconds |
|
While the above example works a good proof-of-concept for functionality, it's not overly useful, so let's look at additional examples.
Example #2: Reformatting Log File Data
Once you have established that you can retrieve data from your custom plug-in, you can start taking advantage of Log Parser's features to process your log file data. In this example, I will use several of the built-in functions to reformat the data:
logparser "SELECT id AS ID, TO_DATE(publish_date) AS Date, author AS Author, SUBSTR(title,0,20) AS Title, STRCAT(TO_STRING(TO_INT(FLOOR(price))),SUBSTR(TO_STRING(price),INDEX_OF(TO_STRING(price),'.'),3)) AS Price FROM 'C:\sample\books.log'" -i:COM -iProgID:Generic.LogParser.Scriptlet
The above query will return results like the following:
| ID | Date | Author | Title | Price |
| ----- | ---------- | -------------------- | -------------------- | ----- |
| bk101 |
10/1/2000 |
Gambardella, Matthew |
XML Developer's Guid |
44.95 |
| bk102 |
12/16/2000 |
Ralls, Kim |
Midnight Rain |
5.95 |
| bk103 |
11/17/2000 |
Corets, Eva |
Maeve Ascendant |
5.95 |
| bk104 |
3/10/2001 |
Corets, Eva |
Oberon's Legacy |
5.95 |
| bk105 |
9/10/2001 |
Corets, Eva |
The Sundered Grail |
5.95 |
| bk106 |
9/2/2000 |
Randall, Cynthia |
Lover Birds |
4.95 |
| bk107 |
11/2/2000 |
Thurman, Paula |
Splish Splash |
4.95 |
| bk108 |
12/6/2000 |
Knorr, Stefan |
Creepy Crawlies |
4.95 |
| bk109 |
11/2/2000 |
Kress, Peter |
Paradox Lost |
6.95 |
| bk110 |
12/9/2000 |
O'Brien, Tim |
Microsoft .NET: The |
36.95 |
| bk111 |
12/1/2000 |
O'Brien, Tim |
MSXML3: A Comprehens |
36.95 |
| bk112 |
4/16/2001 |
Galos, Mike |
Visual Studio 7: A C |
49.95 |
| |
|
|
|
|
| Statistics: |
|
| ----------- |
|
| Elements processed: |
12 |
| Elements output: |
12 |
| Execution time: |
0.02 seconds |
|
This example reformats the dates and prices a little nicer, and it truncates the book titles at 20 characters so they fit a little better on some screens.
Example #3: Processing Log File Data
In addition to simply reformatting your data, you can use Log Parser to group, sort, count, total, etc., your data. The following example illustrates how to use Log Parser to count the number of books by author in the log file:
logparser "SELECT author AS Author, COUNT(Title) AS Books FROM 'C:\sample\books.log' GROUP BY Author ORDER BY Author" -i:COM -iProgID:Generic.LogParser.Scriptlet
The above query will return results like the following:
| Author | Books |
| -------------------- | ----- |
| Corets, Eva |
3 |
| Galos, Mike |
1 |
| Gambardella, Matthew |
1 |
| Knorr, Stefan |
1 |
| Kress, Peter |
1 |
| O'Brien, Tim |
2 |
| Ralls, Kim |
1 |
| Randall, Cynthia |
1 |
| Thurman, Paula |
1 |
| |
|
| Statistics: |
|
| ----------- |
|
| Elements processed: |
12 |
| Elements output: |
9 |
| Execution time: |
0.03 seconds |
|
The results are pretty straight-forward: Log Parser parses the data and presents you with a list of alphabetized authors and the total number of books that were written by each author.
Example #4: Creating Charts
You can also use data from your custom log file to create charts through Log Parser. If I modify the above example, all that I need to do is add a few parameters to create a chart:
logparser "SELECT author AS Author, COUNT(Title) AS Books INTO Authors.gif FROM 'C:\sample\books.log' GROUP BY Author ORDER BY Author" -i:COM -iProgID:Generic.LogParser.Scriptlet -fileType:GIF -groupSize:800x600 -chartType:Pie -categories:OFF -values:ON -legend:ON
The above query will create a chart like the following:
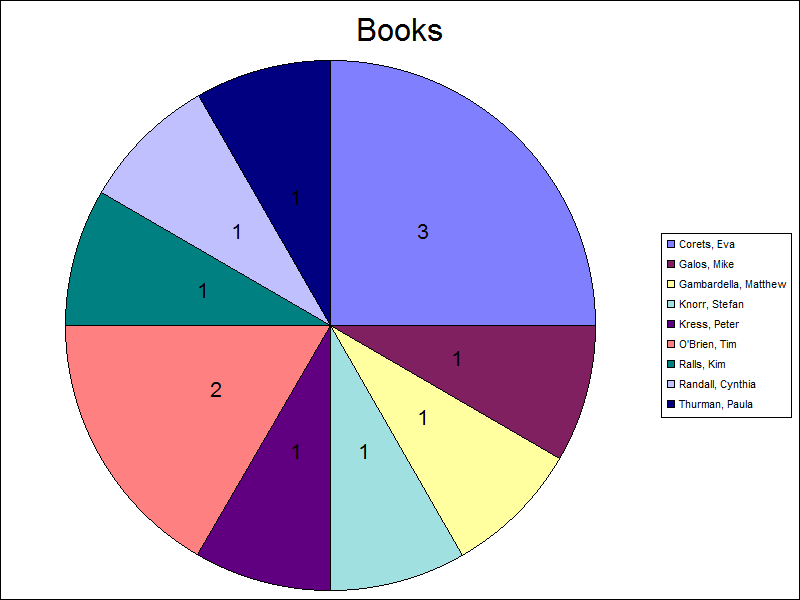
I admit that it's not a very pretty-looking chart - you can look at the other posts in my Log Parser series for some examples about making Log Parser charts more interesting.
Summary
In this blog post and my last post, I have illustrated a few examples that should help developers get started writing their own custom input format plug-ins for Log Parser. As I mentioned in each of the blog posts where I have used scriptlets for the COM objects, I would typically use C# or C++ to create a COM component, but using a scriptlet is much easier for demos because it doesn't require installing Visual Studio and compiling a DLL.
There is one last thing that I would like to mention before I finish this blog; I mentioned earlier that I had used Log Parser to reformat the sample Books.xml file into a generic log file that I could use for the examples in this blog. Since Log Parser supports XML as an input format and it allows you to customize your output, I wrote the following simple Log Parser query to reformat the XML data into a format that I had often seen used for text-based log files:
logparser.exe "SELECT id,publish_date,author,title,price INTO books.log FROM books.xml" -i:xml -o:tsv -headers:ON -oSeparator:"|"
Actually, this ability to change data formats is one of the hidden gems of Log Parser; I have often used Log Parser to change the data from one type of log file to another - usually so that a different program can access the data. For example, if you were given the log file with a pipe ("|") delimiter like I used as an example, you could easily use Log Parser to convert that data into the CSV format so you could open it in Excel:
logparser.exe "SELECT id,publish_date,author,title,price INTO books.csv FROM books.log" -i:tsv -o:csv -headers:ON -iSeparator:"|" -oDQuotes:on
I hope these past few blog posts help you to get started writing your own custom input format plug-ins for Log Parser.
That's all for now. ;-)
Note: This blog was originally posted at http://blogs.msdn.com/robert_mcmurray/